前言
上周在GitHub上一个BettaFish项目很火,再次看到MindSpider项目,以及之前看到的MediaCrawler项目,支持采集多个热门社交平台的相关数据,我将BettaFish在一台老MAC上部署跑起来了(主要逻辑就是在不同渠道不停的搜负面词语。不过针对数据量少的关键字效果一般,只要出现一点错误就会被无限放大),MindSpider & MediaCrawler实在跑不起来,项目太重,每次playwright调起Chromium都被反爬,尝试修复一段时候后担心账号被封还是放弃了。
回头想想垂直领域直接用浏览器插件就可以搞定,大的舆情监测直接花钱买服务或者API接口。
于是周末我用 Trae SOLO 花了半个下午,撸了一个 Chrome 浏览器插件,核心功能:
- 抖音 / 小红书 搜索页 和 详情页 均可一键采集
- 自动识别 一级 与 二级 评论,用
parent_id关联 - 导出 CSV(UTF-8 BOM),Excel 直接打开即可透视
- 全程 0 后端,纯前端离线运行,隐私无上传
下面聊聊技术实现与踩坑。
一、整体架构
├─ manifest.json // 权限声明 + 注入规则
├─ content.js // 页面脚本,负责 DOM 解析、数据缓存、CSV 生成
├─ background.js // 扩展后台,只负责下载文件
├─ styles.css // 悬浮按钮样式
└─ README.md
- content 脚本 同时注入
douyin.com与xiaohongshu.com,按 hostname 自动路由 - 用
Map()做内存数据库,键为videoId / noteId,值为元数据 + 评论数组 - 采集完成后调用
chrome.runtime.sendMessage()把 Blob 传给 background 触发下载
二、核心难点
1. 动态 DOM + 哈希 class
抖音&小红书前端都是 React 同构 + 随机类名,class="HtBH2h0B" 下次就变了。
解法:
- 放弃 class,用 属性 + 层级 选择器
例:一级评论节点[data-e2e="comment-item"]:not([data-e2e="comment-item"] [data-e2e="comment-item"]) - 对表情/换行节点用
.innerText而非.textContent,再replace(/\s+/g,' ')压缩空白
2. 二级评论与一级关联
需求:二级评论要能通过 parent_id 挂回一级,方便后续透视表统计。
解法:
- 以 顶层
[data-e2e="comment-item"]为粒度循环,生成数字序号1、2、3… - 其内部若再出现
[data-e2e="comment-item"](即二级),统一记p1、p2、p3… - 去重键 =
parent_id|user|text|time,同一父级下重复渲染直接跳过
3. 单条采集 vs 批量采集
- 搜索页:用「开始采集」按钮,批量点卡片 → 等评论加载 → 抓数据
- 详情页:右上角注入「采集」按钮,点一下只采当前,不跳转
- 按钮用
position:fixed悬浮,z-index 设 9999,避免被页面覆盖
4. CSV 导出 & 中文乱码
- 前端生成 CSV 必须加 UTF-8 BOM(
\uFEFF),否则 Excel 打开中文乱码 - 文件名带时间戳,防重复:
douyin_comments_20240724_153045.csv - 有数据才 export——空 Map 直接跳过,不写 0 字节文件
5. 评论节点重复渲染(虚拟滚动)
抖音评论区用了 虚拟滚动 + 复用 DOM,同一条评论可能出现 2 次。
解法:
- 在
extractComments()里加 双键去重- 基础键:
user|text|time - 父级键:
parent_id|user|text|time
- 基础键:
- 控制台打印
跳过重复渲染方便调试
三、效果演示
- 打开抖音搜索页 → 右下角「开始采集」

- 控制台实时输出
[DY] 1级评论 45 条 [DY] 2级评论 128 条,总计 173 条 - 点击「导出 CSV」→ 得到
douyin_posts_20240724_153200.csvdouyin_comments_20240724_153200.csv
- Excel 透视:
parent_id='p3'即可看第 3 条一级下的所有二级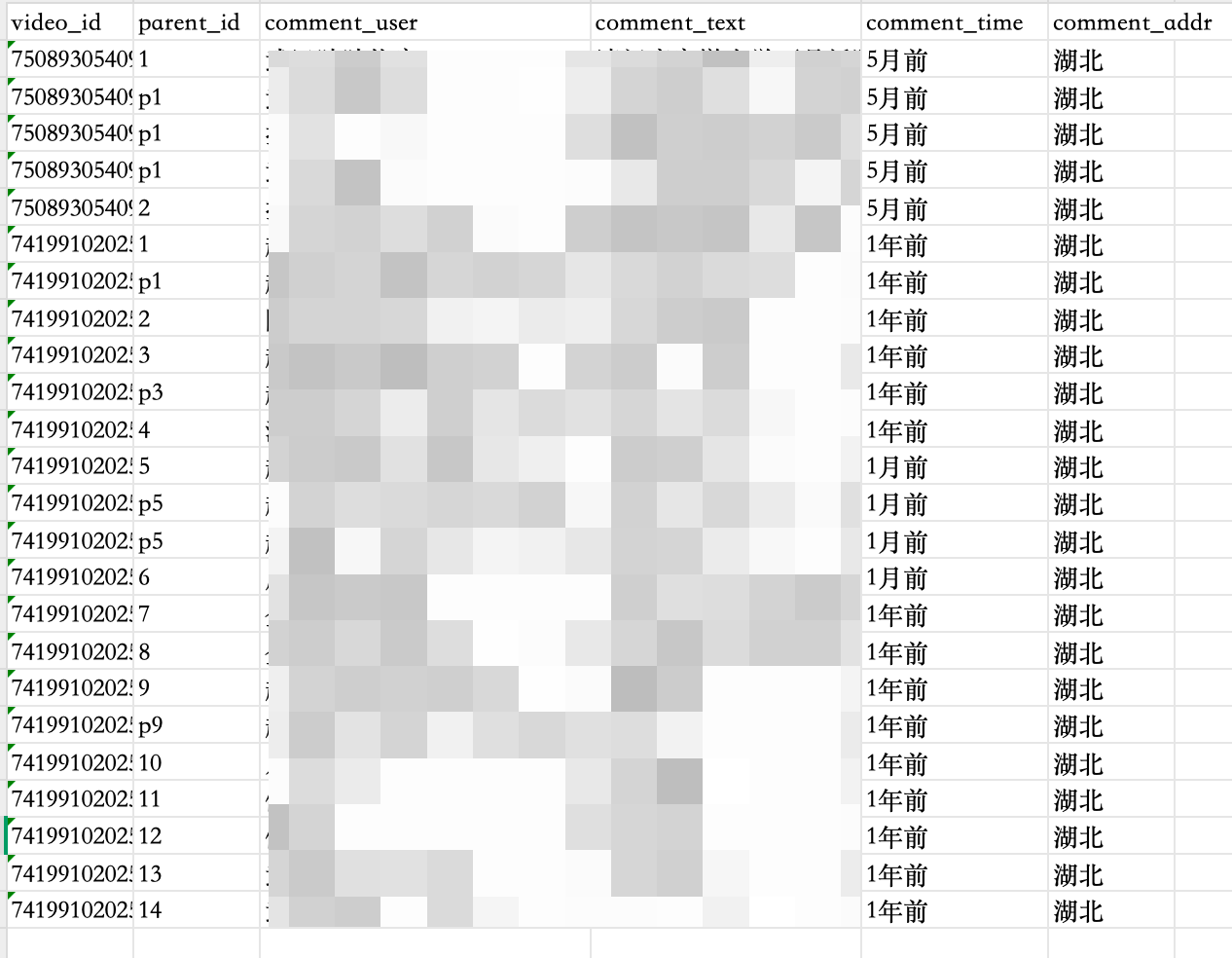
小红书同理,字段完全一致,可直接并表分析。

四、后续可玩方向
- 自动 翻页/滚动 加载更多评论
- 增加 点赞数、IP 属地 等字段
- 打包成 用户脚本(Tampermonkey)免安装
- 用 Web Worker 做流式解析,降低主线程阻塞
工具链:Trae SOLO + Chrome Extension
开发耗时:4 小时(含调试 & 写 README)
代码行数:< 1000 行
最大感受:动态类名面前,属性选择器 + 层级 才是永远滴神 🚀
最后吐槽下没有了Claude的Trae降智太严重,简单的需求来回拉扯很多次。另外希望后期Trae能直接调试浏览器,查看网页元素和输出,这类浏览器插件及偏前端的开发会容易很多。